League of Legends: Championing the Rift with Deep Learning Recommendations
- Bruin Sports Analytics

- Apr 2, 2023
- 16 min read
By: Jun Yu Chen and Eric Xia
Introduction:
Picture yourself on the battlefield of Summoner's Rift, your heart racing with anticipation and your fingers poised to unleash a torrent of devastating abilities on your adversaries. As you gaze upon the vast array of champions before you, a daunting question arises: which champion should you choose? This critical decision can mean the difference between a triumphant victory and a bitter defeat. In an attempt to address this challenge, we present a novel approach aimed at enhancing your champion selection process.
In this article, we explore the realm of deep learning and neural networks, unveiling both content-based and collaborative recommendation systems designed to pair you with the perfect champion in the widely acclaimed multiplayer game, League of Legends. The model operates by analyzing the match-up, player characteristics, and champion features to identify the champion with the highest probability of securing a win. Our prototype is tailored for situations where the other nine champions have been selected, leaving the model to guide you in choosing the final, decisive champion. While not a foolproof solution, this innovative approach offers an exciting glimpse into the potential integration of machine learning, gaming psychology, and strategic decision-making in gaming.
What is LoL?
League of Legends is a multiplayer online battle arena (MOBA) game where players work together to destroy the enemy team's base while defending their own. Each game of league of legends consists of two teams, each made of 5 players with 5 different positions, which are top, jungle, mid, support, and adc. Each position offers a wide selection of champions, and a successful team composition requires a thoughtful selection of five champions. The process of drafting a winning team composition in League of Legends is a complex and daunting task, which requires careful consideration of both the player side and champion side. In order to build an effective recommendation system for champion selection, it is important to understand the intricacies of the drafting process, which is divided into two phases: the ban phase and the pick phase.
During the ban phase, all 10 players have the opportunity to ban a champion that they do not want to play against, removing the banned champion from the pool of available picks. This phase is critical for establishing a successful drafting strategy, as it allows players to eliminate potential threats and disrupt the opposing team's plans.
The pick phase follows a specific "1-2-2-2-2-1" order, with two teams alternating picks until all champions have been chosen. To simplify the task of building a recommendation system, we focused on the perspective of the last player to pick, as this player always has access to information about the champions chosen by their team and the opposing team.
A Gentle Reminder: We understand that some sections of this article may delve into the technical territory, but rest assured that we've done our best to explain the concepts in a more accessible manner. We also aim to provide valuable insights for readers of all skill levels. However, if you're eager to skip the technicalities and dive straight into the fun, feel free to jump to the end of the article where you'll find our interactive dashboard. Enjoy!
Variables
To develop an effective system, we carefully considered a wide range of variables that could impact the drafting strategy, with a focus on capturing the complex interactions between champions, team composition, player preference, and the opposing team's picks. These features could be split into two parts: the player features and champion features:
Player features:
As players often have a preferred playstyle and champion pool, our recommendation system takes into account a player's individual strengths and the champions selected by their teammates and opponents. To do this, we collect a variety of player data, including the player's selected champion, the champions selected by teammates and opponents, the player's team position, their rank tier, their top three most played champions, their total wins and losses, and their win rate(Figure 2, Figure 3). By considering these factors, our model is able to recommend champions that are tailored to the player's individual playstyle and preferences, as well as the needs of the team.


Champion features:
In addition to recommending champions based on player preferences, we also aim to create the best team composition by factoring in the synergy and counter relationships between champions. In total, currently, there are 162 champions.
To achieve this, we gather information about each champion's unique stats and abilities, including hp, hp per level, armor, attack damage, and attack speed, among others. Our model also considers other engineered features, such as the champion with the best synergy, the champion that counters the current champion, and the champion that is countered by the current champion(Figure 5, Figure 6). By leveraging this data, our system can recommend champions that work together effectively and avoid those that may hinder the team's success.


Data Pulling from Riot API
To gather the necessary data, we utilized the RiotWatcher, which is a wrapper API class for Riot Games' official API. By accessing this API, we could obtain comprehensive information about thousands of matches, including champion selections, match outcomes, and player details such as their position, top champions, and win rate.
To streamline this process, we created custom functions that could take a list of players as input and generate a data frame containing all relevant information(Figure 7). However, we encountered several challenges during the data extraction process. One of the most significant obstacles was the slow extraction speed. Since the API can only access match information one at a time, extracting the desired data could be time-consuming. For instance, when we first attempted to query match and player information such as KDA that required extensive computation, it took approximately 4 minutes to read one game match, and we had hundreds of games that needed processing.

To address this issue, we implemented several optimization techniques, such as using the .apply() method in pandas and the map function in Python to parallelize computations. We also simplified the output and avoided looping in the function call whenever possible. Ultimately, we were able to reduce the extraction time to a manageable level, and we collected over 5000 observations in total.

Preprocessing Data
Refine the rows with NaN values and reset the DataFrame index.
Separate the "top_champs_overall" column into individual columns for each top champion and convert the string type into a tuple using ast.literal_eval.
Encode relevant columns in the original DataFrame, such as "champion1-9," using the champion dictionary and encode categorical features like "teamPosition" with LabelEncoder.
Standardize and normalize numerical columns in the champion DataFrame using StandardScaler and MinMaxScaler.
Employ importance scores generated by a Gradient Boosting Machine to select the most significant features in the dataset.
Divide the merged DataFrame into player_df and champion_df, and then split them into training, testing, and cross-validation sets.
Content-based Deep Neural Network Architecture
The objective is to develop a deep learning model that recommends suitable champions for players in League of Legends. The neural network architecture comprises two distinct sub-networks: one dedicated to player features (player_NN) and another for champion features (champion_NN). Player features encompass match-up details such as chosen teammate champions, team position, and enemy champions, along with player-specific information like tier, top 3 champions played, and overall top champions. In contrast, champion features involve attributes such as champion roles, difficulty level, and counter-champions. Both sub-networks share an identical structure, featuring two hidden layers with 256 and 128 nodes, respectively, and ReLU (Rectified Linear Unit) activation functions. Each sub-network's output layer consists of 32 nodes.

Using TensorFlow's Keras API, the player and champion sub-networks are initially constructed. Subsequently, the input_user layer is created to accommodate player features, while the input_item layer is designed for champion features. The outputs of both sub-networks (vu and vm) undergo L2 normalization to ensure they are on the same scale.

The model's output is computed by taking the dot product of the normalized player and champion vectors (vu and vm) and passing the result through a dense layer with a sigmoid activation function. This yields an output ranging from 0 to 1, signifying the likelihood of a player succeeding with the recommended champion.
The model is then compiled using the Adam optimizer, with binary cross-entropy as the loss function, and accuracy as the evaluation metric. Finally, the model is trained on the player and champion feature datasets for 50 epochs, using a random seed for reproducibility.
To recommend a champion for a specific player, the test player's features are replicated for each champion in the dataset (in this case, 162 champions) using the np.repeat function. This generates a new array, test_match, with the player's features duplicated for each champion. The model's predict function is then employed to estimate the success probability for the player with each champion, based on their respective features. The prediction array contains a success probability value for each champion, allowing us to select the top 10 options for our players.
Model Evaluation and Plots
Model 1

Initially, we included all extracted variables to train the model. However, we observed that the training loss decreased significantly while the validation loss increased substantially(Figure 11). This behavior indicates that the model is overfitting the training data, learning the noise in the data rather than the underlying patterns. As a result, it performs well on the training data but fails to generalize effectively to new, unseen data.

This is supported by the fact that the training accuracy increases significantly while the validation accuracy only increases very slightly. As a result, the model's accuracy is relatively low, with a score of 0.5709.
Addressing overfitting
To address this issue, we implemented two strategies. First, we conducted variable selection using the gradient boosting machine algorithm to identify and select the most important features, thereby reducing unwanted noise. Second, we increased the size of our training dataset by retrieving 2,000 additional rows of data from the Riot API. This augmentation helps the model learn more general patterns in the dataset, which is particularly crucial for our case. The complexity and variability inherent in multiplayer games, as well as the interactions between different champion features and the player's skills, make it essential to expose the model to a more comprehensive set of data to improve its ability to generalize and enhance its performance on unseen data.
Model 2
Gradient Boosting Classifier Variable Selection
The 28 features we have for player_df and champion_df are ranked by their importance scores in the model. We chose to exclude "wins" and "losses" due to their high collinearity with "winPct", which may serve as a more comprehensive indicator of a player's winning rate. Furthermore, we decided to remove the least important champion and player features, such as 'freshBlood_encoded', 'attackrange', 'hpregenperlevel', 'spellblockperlevel', and 'veteran_encoded'. These attributes may introduce noise to the neural network. For example, 'veteran_encoded' also appears to be subjectively irrelevant to the game outcome, as it merely indicates whether a player has been participating for an extended period.


Upon analyzing the performance of model 2, it was observed that the training loss decreased significantly while the validation loss increased moderately. This suggests that the model might still be overfitting to the training data, but it is learning better. This inference is supported by the fact that the validation accuracy showed a steeper increasing pattern, indicating that the model is generalizing better.
Furthermore, it is noteworthy that the accuracy score improved by almost 10% from 0.5709 to 0.6657. To note, it is important to acknowledge that the primary objective of this study is not solely limited to the prediction of win or loss. Instead, the study aims to use the winning rate outputted by the sigmoid function to recommend the top 10 champions that have the highest winning rate in a given match. Thus, the level of accuracy is acceptable.

A high precision score indicates that the model is making few false positive predictions(Out of all the games that were predicted as winning, what percentage actually have won), while a high recall score indicates that the model is detecting most of the actual positive instances(Out of all the games that were actually winning, what percentage was detected as a win).
In the case of our model, the precision and recall scores of approximately 0.66 indicate that the model is performing reasonably well in identifying positive instances, neither over-predicting nor under-predicting the positive class. This is a satisfactory result considering the complexity and variability of the dataset, given the numerous factors involved in predicting the success of a specific champion in a League of Legends match.
In light of the aforementioned observations, it can be concluded that model 2 demonstrates improved performance and generalization capabilities compared to its predecessor, and it is deemed suitable for the task at hand.
Recommendation and Refinement
Matching team position and champion tags
At this stage, the model's predict function is used to estimate the success probability for a player with each champion, by replicating the test player's features to match the 162 LoL champions. However, a matching issue arises. The deep neural network seems unable to consistently provide champions that fit the required team position. For instance, in this example, we need a champion for the BOTTOM position(Figure 22).

Ideally, we need champions with the "marksman" role, but the top 10 champions in the outputted DataFrame include several champions with distinctly different roles.

For example, Khazix is a JUNGLE champion with the "assassin" role, and Hecarim is a TOP or JUNGLE champion with the "tank" and "fighter" roles(Figure 23). This would be a serious issue if it remains unresolved. Now, imagine our unsuspecting noobie player, who has no clue about the game, decides to play Hecarim as a BOTTOM laner after using our model. They'll likely struggle against their opponents, and let's not even mention the potential earful from their less-than-impressed teammates(Figure 24). Nonetheless, the output is not a complete failure, as some champions with the correct roles, such as Kaitlyn, Kaisa, and Zeri, are present. Some champions like Belveth might be mistaken for marksmen due to their high attack speed.
To address this issue, we re-examined the "tags" levels in the champion_df and discovered that many of the labels were incorrect. For instance, Nami's tags were ["Assassin", "Fighter"], while they should be ["Mage", "Support"]. The variety of tags was also quite limited. Consequently, we pulled the official "Roles" column from the Riot API, which is much more comprehensive, and relabeled the champions.
Simultaneously, we developed a filtering algorithm that identifies all outputted champions that do not match the team position and move them to the bottom of the DataFrame, ranked by winning rate.
For example, for a player whose team position is UTILITY in figure 27, the recommended top 10 champions from the model are now primarily from the Support role, such as Rakan, Nami, and Shen(Figure 28). The first three columns display the recommended champions ranked by winning rate, winning rate, and roles. The subsequent columns provide additional information, such as their counters and the champions chosen by the other nine players in the game. Champions 1 to 4 are your teammates, while champions 5 to 9 are your opponents.


Limitations of the Recommendation System
Insufficient data:
The current model may suffer from overfitting due to a limited dataset, which might not comprehensively capture the complexity and dynamics of the League of Legends game. Consequently, it compromises its ability to generalize to new, unseen data. To address this issue, we can focus on collecting more data from the Riot API. However, personal users face API pull limits, so it is necessary to request development or production keys that allow for increased pull limits and do not expire every 24 hours. Alternatively, we can explore data augmentation techniques to create new, synthetic data points, expanding the existing dataset.
Inadequate role recognition:
The model has difficulty accurately recognizing and recommending champions that align with the required team positions, leading to inconsistencies between the desired roles and the suggested champions. Although a filtering algorithm has been implemented to alleviate this issue, the neural network itself fails to effectively learn role recognition, suggesting a potential limitation in the model's design or feature representation. To enhance role recognition, we can incorporate additional features or develop a dedicated sub-network focusing on role recognition. This ensures the model learns to recommend champions that correspond to the required team positions more effectively.
Other features:
A significant portion of our features focuses on the chosen champions, their attributes, and the top-played champions of our players. To enhance the model's performance, we should consider incorporating additional features such as average kda that better represent the player's skill level. For instance, we could develop an integrated score that evaluates a player's skill based on their winning rate, the types of champions they play, their tier, and other relevant factors. By including these new features, we may be able to account for more variance in game outcomes, ultimately improving the model's ability to predict wins and losses.
Applicability:
The current model is somewhat simplified, assuming that the other nine champions have been chosen and offering a recommendation for the last player to choose. To create a more realistic recommendation system, we should design the model to accommodate more complex scenarios where a random number (n) of champions have been selected, where n is less than 9. This approach more accurately reflects the dynamic nature of the champion selection process in the game.
Collaborative filtering
In addition to our previous approach, we wanted to consider another factor for players to truly excel in League of Legends - versatility. A strong player should be able to play several champions skillfully, but often players tend to have a specific play style and are limited in their champion pool. Therefore, we decided to incorporate user-based collaborative filtering to recommend champions based on the player's preferences. By doing this, we aim to help players expand their pool of champions, improve their gameplay, and ultimately become more versatile in their gameplay strategy.
User-based collaborative filtering is another widely used technique in creating personalized recommendation systems. The core concept is to find users with similar preferences and suggest items based on the preferences of these similar users. For our use case, we are interested in recommending champions to players in League of Legends, based on their preferences. But how do we determine the preferences of players?
To accurately identify the champion preferences of players, we leverage the champion mastery points system in League of Legends. Champion Mastery points are earned by completing games with a particular champion, effectively tracking a player's investment in different champions. A champion that a player frequently plays will have a higher mastery point value. Using the Riot API, we extracted the mastery point information for over 15,000 players and selected the top five most played champions for each player to form a dataset with mastery point information.

To implement the user-based collaborative filtering, we used the SVD algorithm from the Surprise package in Python. SVD, or Singular Value Decomposition, is a matrix factorization technique that decomposes a large matrix into three smaller matrices to capture the latent features or factors of the data. In our case, the data refers to the champion mastery points for each player. By using SVD, we can identify the underlying preferences of players for certain champions and make personalized recommendations based on these preferences. Additionally, to improve the performance of our model, we scaled the champion mastery points to a scale of 0.5 to 5, effectively normalizing the data for better accuracy.
The main objective of the SVD algorithm is to predict the champion mastery points for new champions that a player has not played before, based on their mastery points for other champions and the preferences of similar players. This is achieved by minimizing the difference between the predicted mastery points and the actual mastery points a player has for a specific champion. The resulting output would be a list of five new champions that players have not played before, sorted from the most to the least similar to their most played champions, based on the preferences of similar players.
During the development of our recommendation model, we encountered a few challenges and limitations. One of the major issues was the significant imbalance in champion popularity among League of Legends players. For instance, champions like Ezreal, Yasuo, and Lee Sin were among the most frequently played champions, while other champions such as Skarner and Corki were rarely played. This imbalance posed a problem for our user-based collaborative filtering recommendation model as it could lead to an over-reliance on popular champions in our recommendations. To address this issue, we randomly downsampled the most frequently played champions to limit their occurrence in our dataset to 400 each, which is approximately the mean number of occurrences for champions. Additionally, we normalized the champion mastery points for popular champions by subtracting the mean mastery points value from each champion mastery point. By doing this, we hoped to ensure that our model would not simply recommend the most popular champions to every player, but instead provide a more diverse set of recommendations based on each player's preferences.

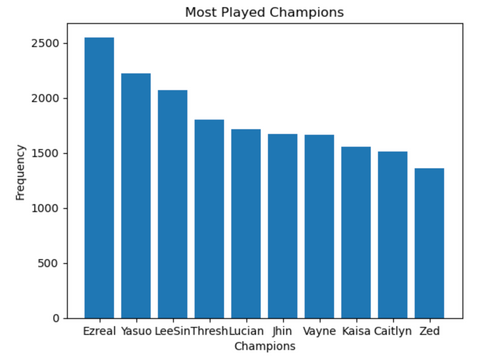

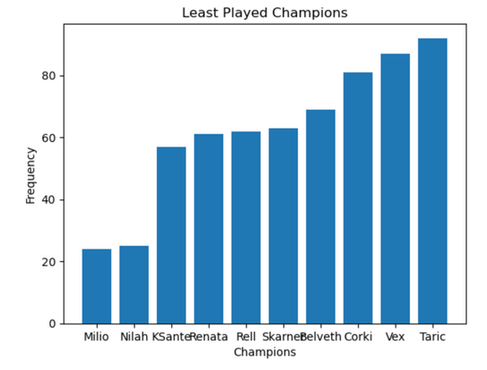
Figures 31: frequency of most played/least played champions
The prediction steps are outlined below:
1. The player enters the top five most played champions and their respective mastery points.
2. The model adds this information to the current mastery points data, then downsample and normalize the data
3. The SVD algorithm is applied to the downsampled and normalized dataset to identify similar players and recommend champions based on their preferences.
4. The model predicts the mastery points for champions that the player has not played based on their mastery points for other champions and the mastery points of similar players.
5. The output is sorted from high to low, providing the player with the top five recommended champions they have not played before but are most similar to their preferences.
Despite our efforts to improve the recommendation model with downsampling and normalization techniques, we were still faced with limitations due to the limited data and imbalanced popularity of champions. As a result, our model had a mean squared error of 1.8, which was not as impressive as we had hoped. Moreover, when we tested the model further, we found that it provided reasonable recommendations in some cases and recommendations that are not very good in others. For instance, for our test player who has high mastery points in Shaco, Rammus, MonkeyKing, Jax, and Zac, and would likely prefer champions in the top or jungle role that are fighters, tanks, or assassins, here is the information being used for prediction.

In that case, the recommendation list generated by our model included Nasus, Yasuo, Pyke, Tristana, and Ryze. Nasus and Yasuo were good suggestions similar to MonkeyKing and Jax. Pyke was an ok suggestion as well since he and Shaco are both assassins with the ability to go invisible in fights. However, Tristana and Ryze were not ideal recommendations, as the player had not played a mid lane, bot lane, or ranged champion before. Overall, our model provided some reasonable suggestions, but there is still much room for improvement in the accuracy of our recommendations.

Deployment
To make this project more engaging and interactive for readers and League of Legends players, we've deployed our trained machine learning model using Streamlit, a powerful tool that seamlessly connects GitHub to a web-based app framework. Deployment allows us to use our model to provide personalized champion recommendations for users.
You can find the exact deployment code in our GitHub repository. Through our interactive web-based dashboard, you can input the 9 champions that your teammates and opponents have chosen, along with some personal player information such as your team position and an estimated win rate, which can be found on op.gg. By the way, "hotstreak" indicates whether you are on a winning or losing streak.
Once you've entered this information, our model will recommend the top 10 champions tailored to your game. Get ready to level up your gameplay and dominate the Rift!
The link to our interactive dashboard is right below:
The link to our Github is right below:
Last words
You've made it to the end of the article! We appreciate you taking the time to read our piece, and as a bonus, we'd like to share two of our favorite champions in League of Legends. We hope you enjoy using our interactive dashboard and that it helps guide you towards many triumphant matches and exciting experiences with new, recommended champions. See you next time!
References:
Comments