New Face of the WNBA? Predicting Caitlin Clark’s Rookie Season Statistics
- Bruin Sports Analytics

- Sep 10, 2024
- 5 min read
By: Angelina Muliadi, Brian Mualim, and Victoria Vivian Chan
Introduction
From March Madness until the WNBA draft, one name emerges time and time again: Caitlin Clark. In her senior season, Clark averaged 31.6 points, 8.9 assists and 7.4 rebounds per game, leading Division I in scoring and assists. She finished with the highest career scoring average (28.42) in Division I history. Beyond the numbers, many credit Clark for revolutionizing women’s college basketball. In a historic moment, during Clark’s senior year, the viewership for the WNCAA finals surpassed that of the men’s final for the first time. As Caitlin Clark transitions into the WNBA as the first overall pick, this begs the question: Will she be able to live up to the hype, or falter under pressure?
Definitions
Before trying to predict Caitlin Clark’s career trajectory, one must first understand the terminologies of the sport.
FG% (Field Goal Percentage): Percentage of shots made throughout the season.
APG (Assists per Game): Average number of passes leading directly to teammate scores per game
PPG (Points per Game): Average points scored by a player per game
RPG (Rebounds per Game): Average times a player gets the ball after a missed field goal
BPG (Blocks per Game): Average number of times a player deflects a field goal attempt
3PT% (3 Points Percentage): Percentage of 3 Point shots made
SPG (Steals per Game): Average number of times a player is able to obtain possession of the ball
Sourcing the Dataset
The dataset was sourced from the NCAA archives. Although its interface is not the most friendly, it has the most complete archive of women’s college basketball statistics. Moreover, we were able to export the datasets for each season as a CSV file.
Methodology
The methodology involves 2 steps:
Finding the top 5 players with the most similar statistics as Caitlin Clark during her senior year of college
Develop a regression model using those 5 players’ WNBA first season worth of career statistics, as well as Sue Bird and Diana Taurasi’s statistics, to predict Caitlin Clark’s rookie season.
For the first step, the researchers used the Euclidean distance between Caitlin Clark’s senior year statistics and every other NCAA player’s as a similarity score, with height and position played as weighted factors as well. Then, players with the five lowest scores were selected to be used for the regression model.
The players selected are:
Odyssey Sim
Rachel Branham
Kelsey Plum
Tan White
Amber Hope
For the second step, these player’s rookie seasons in the WNBA were used as the training data set of the regression model. Additionally, Diana Taurasi and Sue Bird’s rookie seasons were included as Clark is often compared to these 2 legends in mainstream media, and the researchers felt that it was appropriate to include their stats as they are similar heights and positions as well to Clark.
Why Linear Regression for our Model?
Linear regression is a statistical method used to model the relationship between a dependent variable and one or more independent variables by fitting a linear equation to the observed data. This technique is particularly useful for predicting continuous outcomes and identifying the strength and direction of relationships between variables. We chose the linear regression model because it is the simplest form of machine learning, easy to interpret, and straightforward to fit using libraries such as sklearn in Python, making it ideal for initial data analysis and baseline modeling.
The formula for a linear regression model is:

Where:
y is the dependent variable that we are trying to predict
The x's are the independent variables for our predictors
0 is the intercept term (the value of y when all x's are 0)
1, 2, ... , n are the coefficients corresponding to each independent variable
e represents the error term (residuals), accounting for the difference between the observed and predicted values.
To ensure that the dataset is appropriate to be used in a linear regression model, the researchers first performed an exploratory data analysis to understand the structure, characteristics, and quality of the data. This involves checking for missing values and analyzing the distribution of each feature. Then, the data is cleaned to ensure that it is suitable for modeling by handling missing values with appropriate values or by removing rows/columns with too many missing values. Afterward, the data is then split into a training dataset and a testing dataset. The training dataset is further cleaned to only get the numerical values. Then, we can train the model using the training dataset. During this phase, the model learns the patterns and relationships between the input features and the target variable. Next, the testing dataset will be used to evaluate the model's performance. This helps to simulate how the model will perform on unseen, real-world data. Using the training data, we ran multiple linear regression models, each predicting a different target variable (e.g., PPG, APG, RPG, etc.). This approach involves training separate models for each target variable using the relevant features.
Analysis
Code and Predicted Points


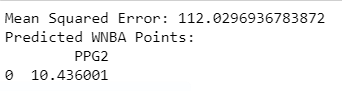
The code for the linear regression model is shown above. The model is used to predict each of the 7 basketball categories individually and the one shown above is used to predict Clark’s PPG. It can be seen that the model has predicted Clark will have a rookie season averaging 10.44 PPG given her senior year of college’s statistics being: 31.6 PPG, 8.9 APG, 7.4 RPG, 1.7 STPG, 0.5 BKPG, 45.5 FG%, and 37.8 3FG%.
However, it should also noted that this model has a particularly high mean squared error (MSE) of approximately 112.03. As the MSE reflects the average squared difference between the actual and predicted values, we conclude that while the model captures some relationships, there is significant room for improvement.
Rest of the Predictions
Statistical Metric | Predicted Stat | MSE |
APG | 1.95 | 0.35 |
RPG | 2.59 | 15.53 |
STPG | 0.53 | 0.16 |
BKPG | 0.41 | 1.38 |
FG% | 38.5 | 62.90 |
3FG% | 32.42 | 52.64 |
As seen from the table above, the metrics that are most accurately predicted according to the model are Clark’s APG, STPG, and BKPG as they all have low MSE. While FG% and 3FG% have high MSEs, it should be noted that these metrics have generally more variance than the rest of the metrics as they’re percentages and not raw numbers. The worst-performing metric is the RPG with an MSE of 15.53. This is probably due to some guards being taller than others, which means that they are more likely to receive rebounds than shorter ones.
Conclusions/Improvements/Limitations
Initially, the researchers wanted to do a regression model with all 4 years of all NCAA Women’s Basketball players as the training dataset. However, there was limited data available in this regard, as the NCAA only limits entries to the top 500 players per statistical category. For example, if you were looking for the statistics of a point guard who scored 20 points per game but only averaged 1 rebound per game, her points data would show up, but not her rebound data. A more complete database would have allowed us to provide a more comprehensive analysis of Clark’s rookie statistics.
Our similarity scores are based on the Euclidean distance, which relies on getting the difference of the square root of the squared sum of all of Clark’s metrics compared to another player’s. The researchers weren’t able to perform analysis on which distance would be most appropriate and settled on Euclidean by default. In hindsight, maybe the Manhattan distance would be better suited for this data as it compares the distance between each individual metric to each other.



Comments